-
[Spark] 아파치 스파크 개념 정리중Data miner/Development log 2021. 2. 17. 18:32728x90
-
스파크는 컴퓨터 클러스터에서 작업을 조율하는 프레임워크. 클러스터의 데이터 처리 작업을 관리 및 조율. 데이터프레임의 추상화를 통해 대용량의 데이터 처리 가능. 스트림처리, 그래프처리, SQL, 머신러닝 기능 제공
-
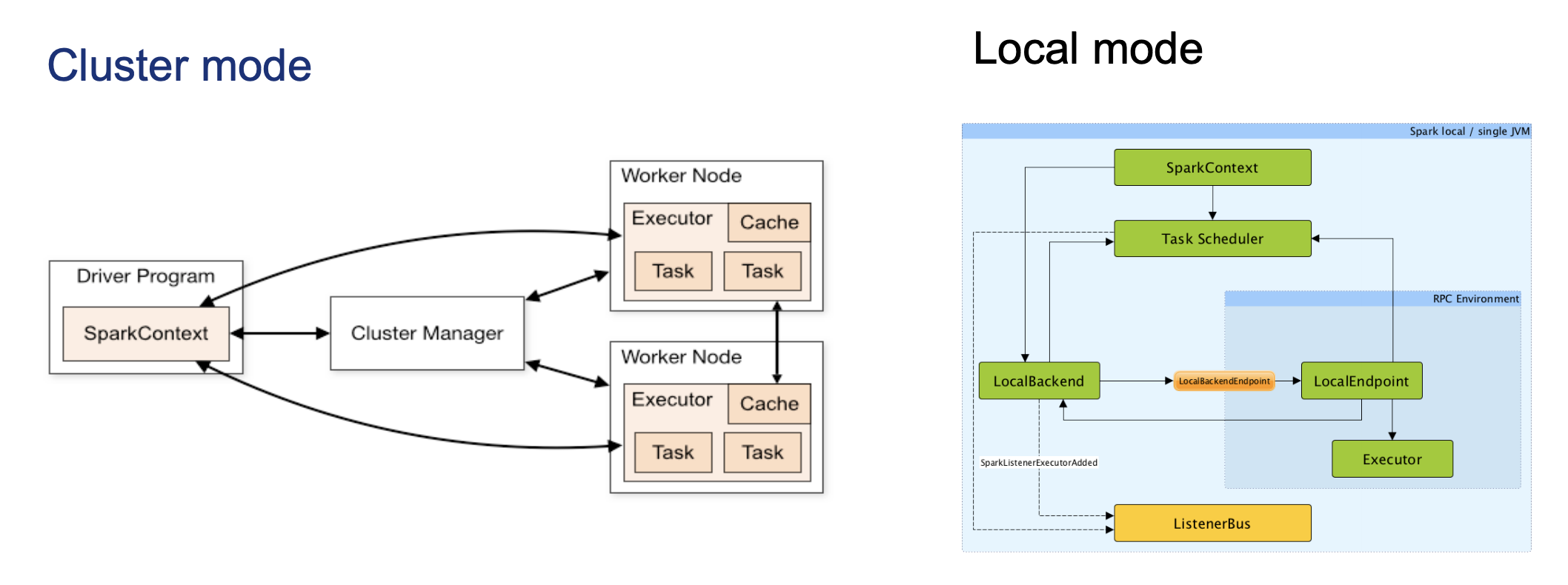
스파크 애플리케이션은 드라이버 프로세스(driver process) 와 익스큐터 프로세스(Executors)로 구성
-
드라이버 프로세스는 스파크 애플리케이션의 중심 본체로서, main()함수 실행 및 SparkContext를 생성함
-
익스큐터 프로세스는 드라이버 프로세스가 할당한 작업을 수행. 드라이버가 할당한 코드 실행/ 진행 상황을 다시 드라이버 노드에 보고
-
-
스파크 스트리밍 : 다양한 데이터 소스에서 유입되는 실시간 스트리밍 데이터를 처리하는 프레임워크
-
장애가 발생하면 연산 결과를 자동으로 복구
-
함수형 프로그래밍을 사용할 수 있는 정교한 API 제공
-
-
python에서 작동하는 스파크(PySpark)는 여러 프로그래밍 모델을 함께 사용할 수 있다는 장점
-
예) 1) Spark를 이용해 대 규모의 ETL 작업 수행 2) Pandas 라이브러리를 활용해 해당 결과에 대한 추가 작업 진행
-
다만, 성능 저하가 있을 수 있다. 파이썬 데이터를 스파크와 JVM에서 이해할 수 있도록 상호 변환하는 과정에서 비용이 발생하기 때문이다.
Dataframe/ Dataset
-
비타입형 Dataframe : 스키마에 명시된 데이터 타입의 일치 여부를 런타임 때 확인
-
타입형 Dataset : 스키마에 명시된 데이터 타입의 일치 여부를 컴파일 타임에 확인
Dataframe
-
Spark의 Dataframe은 여러 컴퓨터에 분산하여 처리할 수 있음
-
스키마 : 컬럼과 컬럼의 타입을 정의한 목록을 일컫는 말
-
파티션: 모든 익스큐터가 병렬로 작업을 수행할 수 있도록 파티션이라 불리는 청크 단위로 데이터를 분할
-
트렌스포메이션 : 데이터를 생성한 후 변경하고자 할 때, 스파크 앱에 데이터 프레임을 변경하는 명령. 변경 코드가 명령이 미치는 범위에 따라 좁은 의존성과 넓은 의존성으로 나뉨
-
액션 : 실제 연산을 수행하기 위해서 내리는 명령
-
1) 변경 코드에 해당하는 데이터 로우 개수 출력
-
2) 콘솔에서 데이터를 보는 액션
-
3) 각 언어로 된 네이티브 객체에 데이터를 모으는 액션
-
4) 출력 데이터소스에 저장하는 액션
-
구조적 스트리밍
-
스파크 2.2 버전에서 안정화된 스트림 처리용 고수준 API
-
구조적 스트리밍을 사용하여 구조적 API로 개발된 배치 모드의 연산을 스트리밍 방식으로 실행 가능, 지연 시간 단축
구조적 API 기본 연산
스키마
-
DataFrame의 컬럼명과 데이터 타입을 결정
-
DataFrame의 컬럼명과 데이터 타입을 정의. 데이터를 추출(Extract), 변환(Transform), 적재(Load)를 수행하는 작업에 스파크를 사용한다면, 스파크를 정의해야 한다. 정의하지 않을 경우, 스키마 추론 과정에서 스키마를 임의로 결정할 수 있다.
-
스키마는 여러 개의 StructField 타입 필드로 구성된 StructType 객체
-
StructType(컬럼의 이름, 데이터 타입, 컬럼의 값이 null값일 수 있는지 지정 True/False 및 메타데이터 지정)
org.apache.spark.sql.types.StructType = ... (StructType(StructField("Specific_Column_name", StringType, true), StructType(StructField("Specific_Column_name", LongType, true),... )구조적 API 실행 과정
- 1. 코드 작성
- 2. 논리적 실행 계획으로 변환
- 3. 물리적 실행 계획으로 변환 및 최적화 할 수 있는지 확인
- 4. 스파크 클러스터에서 물리적 실행계획 실행
'Data miner > Development log' 카테고리의 다른 글
[Spark] [python] Spark Application (0) 2021.03.05 [Spark] [python] 구조적 API 기본 연산 (0) 2021.03.01 [python] [pandas] 특정 칼럼에 속한 unique한 값의 개수 구하기 (0) 2021.01.22 [python] [pandas] 특정 칼럼 기준으로 값이 개수 구해서 새로운 칼럼에 추가하기 ( = 엑셀의 countif 함수) (0) 2021.01.20 [tf.Keras] Keras.models의 Model과 keras.layers의 Lambda (0) 2021.01.15 -