-
Data AugmentationData miner/Development log 2021. 1. 7. 17:30728x90
- 이미지 분류 작업을 한다고 가정해보자. 모델을 충분하지 않은 데이터로 학습시킬 경우, 학습데이터에 존재하지 않은 분류 클래스별 특징으로 인해, 모델의 정확도가 떨어질 수 있다. 이 경우, 이미지를 단순히 변형시키는 방식으로 Augmentation으로 하여, 모델의 정확도를 향상시킬 수 있다. 아래의 사진을 보자. 왼쪽 고양이의 원본 사진은 고양이의 귀가 위를 향한 사진이었다. 누워 있는 고양이를 식별하기 위해서, 우리는 왼쪽 사진을 오른쪽으로 45도 정도 회전시켜 학습시킬 수 있다. 우리가 기대하는 효과는, 누워있는 고양이의 귀의 특징을 변형된 왼쪽 사진을 활용해 학습시키는 것이다.
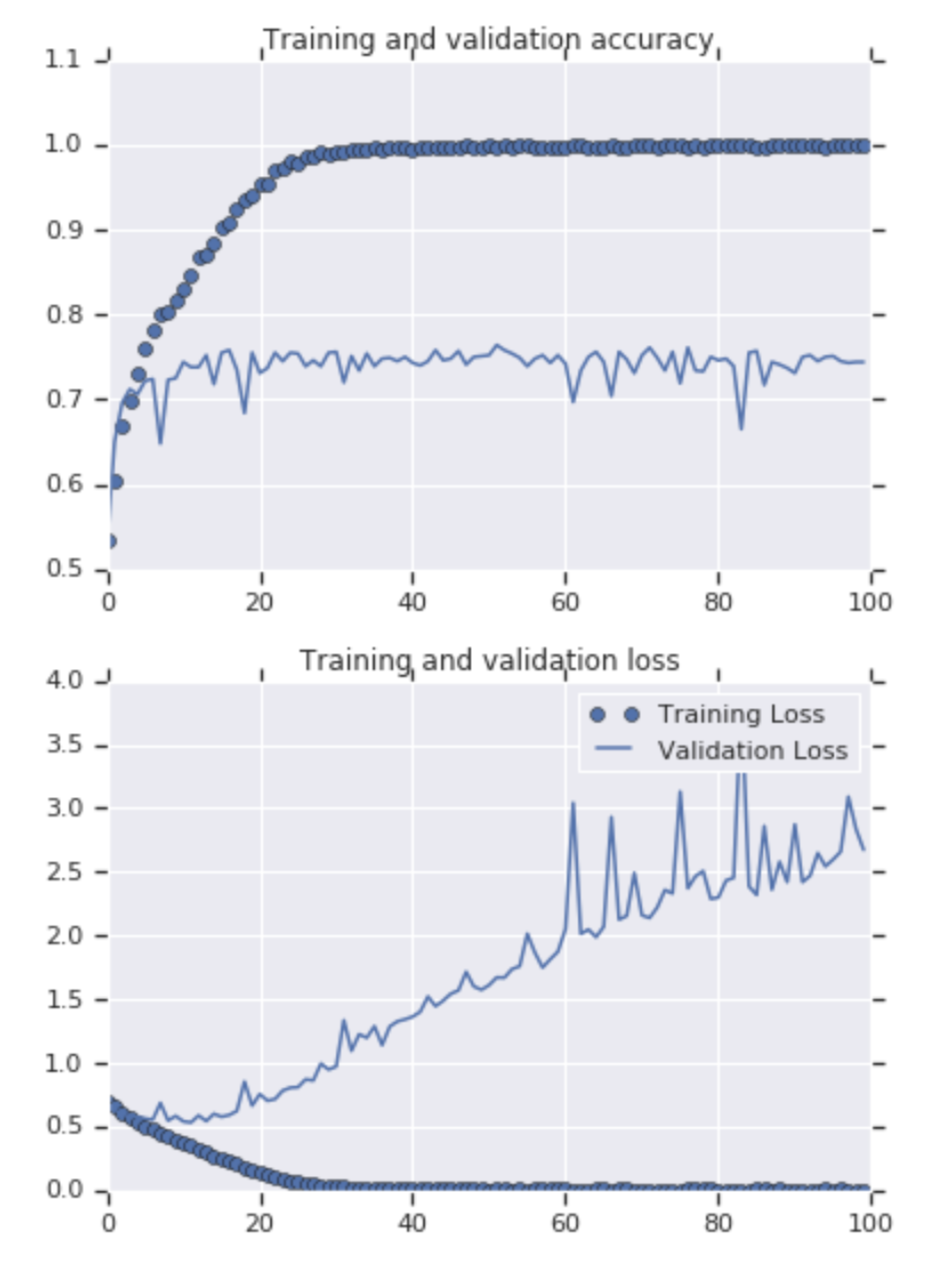
이미지 분류 작업에서, Data Augmentation 이 필요한 경우, 위의 차트와 같이 Training accuracy와 Validation accuracy가 차이가 많이날 때 사용한다. 
- Data augmentation는 Keras의 preprocessing의 ImageDataGenerator의 클래스를 활용할 수 있다.
tf.keras.preprocessing.image.ImageDataGenerator( featurewise_center=False, samplewise_center=False, featurewise_std_normalization=False, samplewise_std_normalization=False, zca_whitening=False, zca_epsilon=1e-06, rotation_range=0, #이미지를 0도에서 180도 사이로 회전하기 width_shift_range=0.0, #이미지의 프레임을 이동하기 (대부분의 피사체가 중앙에 위치하기 때문에, 이미지 프레임 이동으로 모델이 다양한 특징들을 학습 가능) height_shift_range=0.0, # brightness_range=None, shear_range=0.0, #이미지를 비틀기. 피사체를 왜곡시킨다 zoom_range=0.0, #이미지를 확대하기 channel_shift_range=0.0, fill_mode="nearest",#이미지 해상도가 깨진 경우, 주변 화소를 참조하여 빈 공간을 채우게 된다. cval=0.0, horizontal_flip=False, #수평뒤집기 vertical_flip=False, rescale=None, preprocessing_function=None, data_format=None, validation_split=0.0, dtype=None, )(참고 : keras.io/api/preprocessing/image/ )
- 그러나, Data augmentation이 모든 경우의 Validation accuracy를 높여줄 수 있는 것은 아니다. 모델 학습시, 이미지를 무작위적으로 변형하여 증강시키기 때문에, Validation 이미지가 무작위적으로 존재하지 않을 경우, Validation시의 정확도의 변동성은 커질 수 있다.
- Data augmentation시, 실제 디스크의 용량을 차지하는 것이 아니라 memory만 사용하게 된다.
'Data miner > Development log' 카테고리의 다른 글
[python] [pandas] 특정 칼럼 기준으로 값이 개수 구해서 새로운 칼럼에 추가하기 ( = 엑셀의 countif 함수) (0) 2021.01.20 [tf.Keras] Keras.models의 Model과 keras.layers의 Lambda (0) 2021.01.15 [python] [pandas] encoding='cp949'로 저장하는데 에러 발생 문제 (0) 2020.10.15 [python] [pandas] index 활용하기 (0) 2020.10.15 [python] [pandas] column의 원소가 np.array로 구성되어 있을 때, list로 변경하기 (0) 2020.09.07