-
[논문리뷰] Cold-start aware user and product attention for sentiment classificationData miner/Information Retrieval 2020. 9. 23. 23:57728x90
리뷰한 논문 - Amplayo, R. K., Kim, J., Sung, S., & Hwang, S. W. (2018). Cold-start aware user and product attention for sentiment classification. arXiv preprint arXiv:1806.05507.
감성분석(Sentiment Anlaysis)은 사용자가 특정 컨텐츠/제품에 대해 리뷰를 남기면, 이에 대해서 긍정/부정으로 분류하는 분석이다. 최근에는 감성분석과 관련한 연구가 개인화에 초점화를 맞추고 있으며, 이는 구체적으로 특정 유저에게 유저의 취향에 맞는 제품을 추천하기 위해서다. 유저와 제품의 주변 정보(유저/제품과 유사한 다른 유저/제품 정보)를 활용해야 하는 이유는 크게 두 가지가 있다.
1) 개개인이 작성하는 단어나 표현 방식은 감성의 극성으로 분류하는데 있어서 개개인의 편차가 존재한다. 예를 들면, 특정 음식을 평가하는데 있어서 "매우 맵다"라는 정보는 매운 음식을 선호하는 사람에 따라 다를 것이다.
2) 콜드 스타트(Cold start) 사용자/제품의 문제가 있다. 사용자/제품의 과거 정보가 불충분할 때 발생하는 문제다. 사용자가 과거에 선택한 아이템의 정보가 부족하거나, 혹은 제품에 대한 리뷰 정보 등 평가 정보가 부족할 경우 사용자가 특정 제품에 대해서 긍정 혹은 부정 평가를 내리는지 판단하기가 쉽지 않다. 이에, 특정 유저를 평가하는 데 있어서 유저와 비슷한 다른 유저들을 모델 학습에 사용하며, 제품에 대해서도 마찬가지이다.

논문에서 제시한 Hybrid Contextualized Sentiment Classifier(HCSC) 본 논문에서 제시한 모델은 하이브리드형 문맥 극성 분류기(Hybrid Contextualized Sentiment Classifier, HCSC)는 빠른
하이브리드형 문맥 워드 인코더와 어텐션 메커니즘을 활용한 Cold-start aware attention을로 구성되어 있다.

1. 단어 인코더에서는 워드 근방의 정보와 전체 문장의 포괄적인 정보를 포함하였다.
- CNN+RNN모델 사용. 단어의 지엽적인 정보를 포함하기 위해서 CNN을 전체 문장의 정보를 포함하기 위해 Bi-LSTM 사용.
특히, CNN과 bi+LSTM의 모델로 인코딩된 단어벡터를 단순히 병합하는 것이 빠르게 학습될 뿐만이 아니라, 지엽적 혹은 글로벌한 정보를 효과적으로 담아냄.
2. 콜드 스타트 문제를 해소하기 위해, attention 개념을 활용한 모델 파트가 있다.
- 사용자 콜드 스타드 문제와 제품 콜드 스타드 문제를 해소하는 파트가 각각 존재.
- 이 부분은 크게 distinct pooled vector, shared pooled vector, frequency-guided selective gate로 구성됨.
- Distinct pooled vector : 사용자의 문맥 백터

- Shared pooled vector : 특정 사용자와 유사한 성향을 지닌 사용자들의 정보를 활용하기 위한 벡터

- Frequency-guided selective gate : 특정 유저가 콜드 스타트 유저인지에 따라서 Distinct pooled vector 혹은 Shared pooled vector를 선택할지에 대한 weight를 결정하는 셀 게이트. 베이불 누적 분포 함수(Weibull cumulative distirbution)를 활용.gu값은 distinct pooled vector에 곱해지는 weight로서, 콜드 스타트가 아닐 확률로 해석할 수 있다. f(u)는 유저가 쓴 리뷰의 수. Ku와 λu는 사용자마다 다르게 학습되는 형상 벡터와 스케일 벡터. gu의 값은 사용자의 과거 누적된 리뷰 수가 늘어날 수록 커지며, 이는 자연스레 distinct pooled vector의 비중을 키운다.
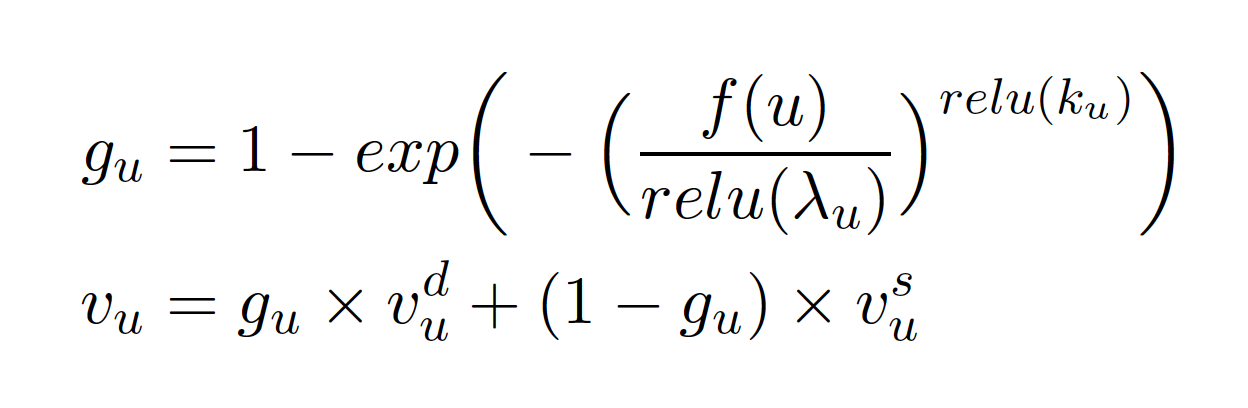
- 사용자와 제품 각각에 대한 specific pooled vector가 만들어지면, (위의 마지막 식에서 Vu 부분) 이를 단순히 병합하여, 시그모이드 함수를 통해 게이트 벡터를 만들 수 있다.
- 게이트 벡터를 사용하여 사용자, 제품에 대한 specific pooled vector를 곱해 최종 하나의 pooled vector를 만든다.

3. 모델로 산출되는 Vup 를 소프트 맥스 함수에 넣어서 제품과 유저의 감성 극성 클래스를 예측한다(y'). 소프트 맥수 함수를 거쳐나온 값(y')은 감성 극성 클래스의 총 개수의 차원의 벡터값 표현되며, 각 벡터 원소의 값은 해당 클래스에 속할 확률을 나타낸다. 손실함수로서 크로스엔트로피 함수를 사용한다.

3-1. 특히, 학습시에 사용되는 7개의 pooled vector는 동일한 벡터 스페이스에 표현된다. 이 pooled vector들이 attention을 거친 인코딩된 단어 벡터 혹은 선택적 게이트을 통한 부모 풀링 벡터의 가중치 합계를 사용하여 생성된 벡터이기 때문이다. 이러한 특성은 학습시에 이점을 갖게 한다. 왜냐하면 손실 함수 계산시에, 각각의 풀링벡터를 개별적으로 구할 수 있다.
4. '언제 유저/제품이 콜드 스타트에 있다고 볼 수 있을까'라는 연구 질문에 있어서는 명확하게 가이드 내릴 수 있는 기준 지점(cut-off)을 정할 순 없다. 사용자가 문제 상황에 따라 적정 수준을 정해야 한다. 다만, 이 논문에서는 유저/제품이 보유하고 있는 리뷰 수에 따른 게이트 웨이트를 보여줌으로써, 콜드 스타트 문제에 있는지 간접적으로 판단하게 하였다. 두 오픈 데이터셋의 결과에서 알 수 있듯이, 모델은 유저에 대해서는 리뷰가 적었을 때에도 상대적으로 너그럽게 콜드 스타트가 아니라고 판단하고 있다.

'Data miner > Information Retrieval' 카테고리의 다른 글