-
[논문리뷰] Relational Collaborative Filtering_Modeling Multiple Item Relations for RecommendationData miner/Information Retrieval 2021. 3. 15. 06:54728x90
논문 출처; Xin, X., He, X., Zhang, Y., Zhang, Y., & Jose, J. (2019, July). Relational collaborative filtering: Modeling multiple item relations for recommendation. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 125-134)
본 논문은 두 레벨의 구조를 통해서 좀 더 정교하게 유저의 선호도를 모델링하고자 한다. 1) 먼저, 두 가지 아이템의 특성/속성 정보를 모델링 하는데 포함시킨다. 이를 논문에서는 관계성 유형은(Relation type)이라고 하며, 영화로 치면 장르거나, 감독과 같은 아이템의 속성 정보에 해당한다. 본 논문에서는 두 아이템의 추천 유사성의 정도(collaborative similarity)도 관계성 정보에 포함시킨다. 2) 또한, 각 관계성 유형에 해당하는 정도도 모델링하는데 있어서 사용한다. 두 영화가 장르도 같고, 감독도 똑같다면 두 아이템의 유사성의 정도가 높을 것으로 예상할 수 있다. 유저들은 두 아이템의 유사성을 평가하는데 있어서, 관계성 유형에 대해서 얼마나 유사한지에 각기 다른 weight를 줄 수 있다 (The relation values provide important clues for scrutinizing a user’s preference, since a user could weigh different values of a relation type differently when making decisions).
즉, 본 논문은 아이템에 대한 유저의 선호도를 파악하기 위해서 관계 유형(Relation type)과 관계값(Relation value)의 두 차원에서 두 아이템의 관계를 파악하고자 한다.
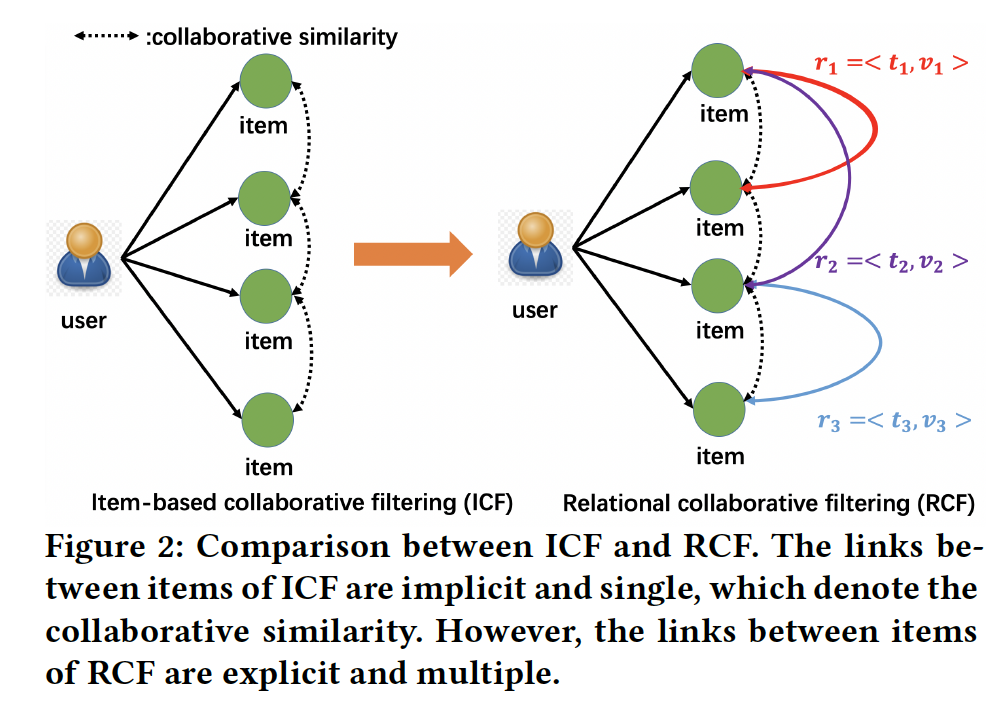
문제 정의
전통적인 ICF의 경우, collaborative similarity를 기존에 존재하는 아이템끼리의 co-interact 패턴에 기반하여 구하였다. (위의 그림의 왼편). 하지만, 현실 세계에 존재하는 아이템 사이에, 아이템별로 다양한 유형의 관계가 있을 수 있다. 논문에서는 아이템 사이의 관계의 정도를 다음과 같이 정의하였다.
item(i,j)의 관계성은 <t,v> = <릴레이션의 종류, 릴레이션의 값>즉, 위 그림에서 오른편에 해당하는 Relational Collaborative Filtering은 아이템 사이의 잠재적인 collaborative similarity뿐만( co-interact patterns of items)이 아니라 아이템 사이의 다양한 관계도 학습하고자 한다.

유저-아이템 선호도 모델링
본 논문에서는 계층적인(hierarchy) attention-based model을 통해서 user-item의 선호도를 학습한다. 한 유저에 있어서, 특정 아이템과 다른 아이템과의 점수를 파악하는데 있어서, 다음의 정보를 활용한다.
- 1-1 유저의 소비한 과거 기록 정보에 기반한 아이템 정보 : 유저의 과거 기록 정보에 기반한 아이템들은 어떤 특정 아이템(타겟 아이템)과 관계성 정보(t)를 가진다.
- 단, 여기서 말하는 특정 아이템은 유저가 소비한 아이템이며, 유저가 소비한 아이템 사이들의 관계를 모델링하는 것이다.
- 1) 하나의 아이템과 특정 아이템은 다양한 관계를 가질 수 있다.
- 2) 특정 아이템과 유저가 소비한 다른 아이템 사이에는 직접적으로 관계가 없을 수도 있다. 두 아이템 별 겹치는 장르나, 감독, 등장인물이 없을 수 있다. 하지만, 아이템의 성격이 직접적으로 연관이 없더라도, 유사할 수 있다. 이런 경우도 latent relation r0 = <t0, v0> 으로 학습한다. r0은, co-interact pattern으로 볼 수 있다.
- 관련 코드 내용)
def get_relational_data(user_id, item_id, data): # user, positive, negative, alpha = [], [], [], [] r0, r1, r2, r3 = [], [], [], [] ... if len(shared_genre) + len(shared_director) + len(shared_actor) == 0: r0.append(another_item) ...- 1-2 유저는 특정한 영역을 특히 더 강하게 선호할 수 있다. (ex, user 1은 로맨스 보다 공상과학 영화를 선호한다.) 이 정보를 두 번째 단계에서 학습한다. 다만, 아이템 사이에는 다양한 관계가 있을 수 있어 일반적인 softmax함수로는 학습이 잘 일어나지 않았다. smoothed softmax 함수를 사용한다.
- 유저가 소비한 아이템에 높은 순위를 주기 위해서 BPR pairwise learning framework를 적용한다.
아이템-아이템 관계 데이터 모델링
일반적으로, 관계성 데이터를 모델링하는데 있어서 Directed Knowledge graph를 사용할 수 있으나, 이 문제에서는 적용하기 어렵다.
1) 아이템 관계는 두 개의 레벨을 가지고 있다. <아이템 사이의 일치되는 영역에 대한 정보, 그 영역의 구체적인 정보> (예를 들면, <두 아이템의 공통된 장르, 공상과학>) 이러한 형태는 일반적인 KGE 형태가 아니다.
2) 아이템 관계는 하나의 방향의 그래프가 아닌, 양방향의 그래프 형태를 띈다. KGE의 학습으로는, e1 + r = e2, e2+r = e1이기 때문에, r이 0에 수렴한다.
따라서 각기의 문제를 다음과 같은 방식으로 해결하였다
1) 문제의 경우, 두 아이템의 관계성을 나타내는 타입 정보와 값을 합치는 방식으로, r = xt + Zv 학습하였다. xt 은 관계 타입을 뜻하며, Zv는 관계 타입에 따른 값을 뜻한다.
2) 문제의 경우, f(e1, r, e2) = f(e2, r, e1) 교환법칙이 성립하도록 학습하는 KG를 선택하였다.
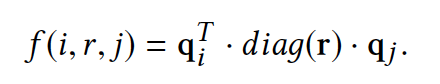
여기에서도 BRP loss를 적용하여, 목적함수가 과거 소비한 아이템들을 높은 점수를 주게 한다.
BPR Pairwise learning Framework / BPR Loss
유저-아이템 선호도 / 아이템-아이템 관계 모델링 하는데 사용되는 손실함수는 "BPR: Bayesian personalized ranking from implicit feedback" 논문에서 제시된 BPR 방식을 따른다. 유저-아이템 선호도 관계 모델링에 있어서, 유저가 소비한 아이템의 스코어를 소비하지 않은 아이템의 스코어보다 높게 학습하는 방식이다. 이는 구체적으로 유저가 소비한 아이템의 점수에서 소비하지 않은 아이템의 점수를 뺀 차이를 크게 만들도록 학습한다. 마찬가지로, 아이템-아이템 관계 모델링 파트에서는, 아이템 사이의 관계가 존재하는 경우의 점수에서 아이템 사이의 관계가 존재하지 않는 경우의 점수를 뺀 값을 크게 만들도록 학습한다.
'Data miner > Information Retrieval' 카테고리의 다른 글